
Understanding the Difference Between the Two
Two Systems. Two Sets of Rules. Your Website. One of the Past, the Other Your Future
WHAT YOU’LL FIND IN THIS ARTICLE
Most small businesses have spent years optimizing for Google, and its nebulous abyss of an algorithm. With the advent of AI, the way the LLMs bring the answers to those who ask them questions isn’t widely known. What almost no one knows is that this new, completely separate technical infrastructure has quietly built up alongside Google’s, operating on different architecture, different signals, and different rules — and that being perfectly optimized for one does not mean being visible to the other. This article gives you the complete, practical picture of how Google indexing and AI indexing actually work, why they are architecturally different at their core, what the specific technical gaps are that most businesses have never addressed, and the exact actions that close those gaps. Here is what is inside:
- The two pipeline comparison — how Google and AI systems process your website differently at every step
- The crawler ecosystem map — the 15+ bots now visiting your site and what each one actually does
- The robots.txt crisis most businesses don’t know they have — how default settings may be blocking AI visibility right now
- The three-tier AI crawler framework — training vs search vs user-action, and why treating them the same is a costly mistake
- The passage-level extraction mechanism — the RAG architecture that determines whether your content gets cited or ignored
- The entity recognition gap — why Google knows your page but AI may not know your business
- The complete visibility factor comparison — ten signals ranked for both systems, with the action each requires
- The robots.txt strategic decision framework — exactly which bots to allow, which to block, and why
THE ASSUMPTION THAT IS COSTING YOU VISIBILITY
You have a website. In the not-so-distant past, it could be indexed by Google. When people searched for what you do, they’d potentially find you — or close enough. The SEO (Search Engine Optimization) work was done. The visibility problem was solved.
This assumption was accurate for a long time. Since May of 2025, it is not as simple as it was – and all those years of stroking what you thought that beast of an Algorithm at Google would want (Keyword-Centric) is no longer central to what matters most for the ever-growing segment of buyers who consult AI before they consult Google.
Here is the technical reality that most small business owners have never been told.
Google’s spiders and AI crawlers solve different problems. Google spiders build an index of web pages organized by relevance signals like keywords, keyword phrases, backlinks, and user engagement. AI crawlers harvest and analyze content to support LLM retrieval, RAG-based systems, and AI answer generation.
These are not variations on the same system. They are categorically different architectures with different inputs, different processing mechanisms, and different outputs. A business optimized exclusively for Google’s architecture is optimized for one and largely untested for the other. At their core, how Google used to index websites and how all LLMs are doing it now as a prediction system – it encodes vast amounts of training data into neural networks and generates contextually relevant answers directly. While Google asks, “Where is this information?” AI asks, “What is the most relevant response?” This distinction fundamentally changes how content is discovered, ranked, and presented to users, creating two parallel but increasingly interconnected information ecosystems.
The gap between those two states is the gap between appearing in Google’s results list and being named in an AI’s recommendation. And as the research throughout this series has established, the buyers who use AI to find service providers convert at 4.4 times the rate of organic search visitors.
You already did the work to build something worth finding. The question is whether the infrastructure exists to let AI systems find it.
This article answers that question — completely, technically, and with the specific actions that close every gap.
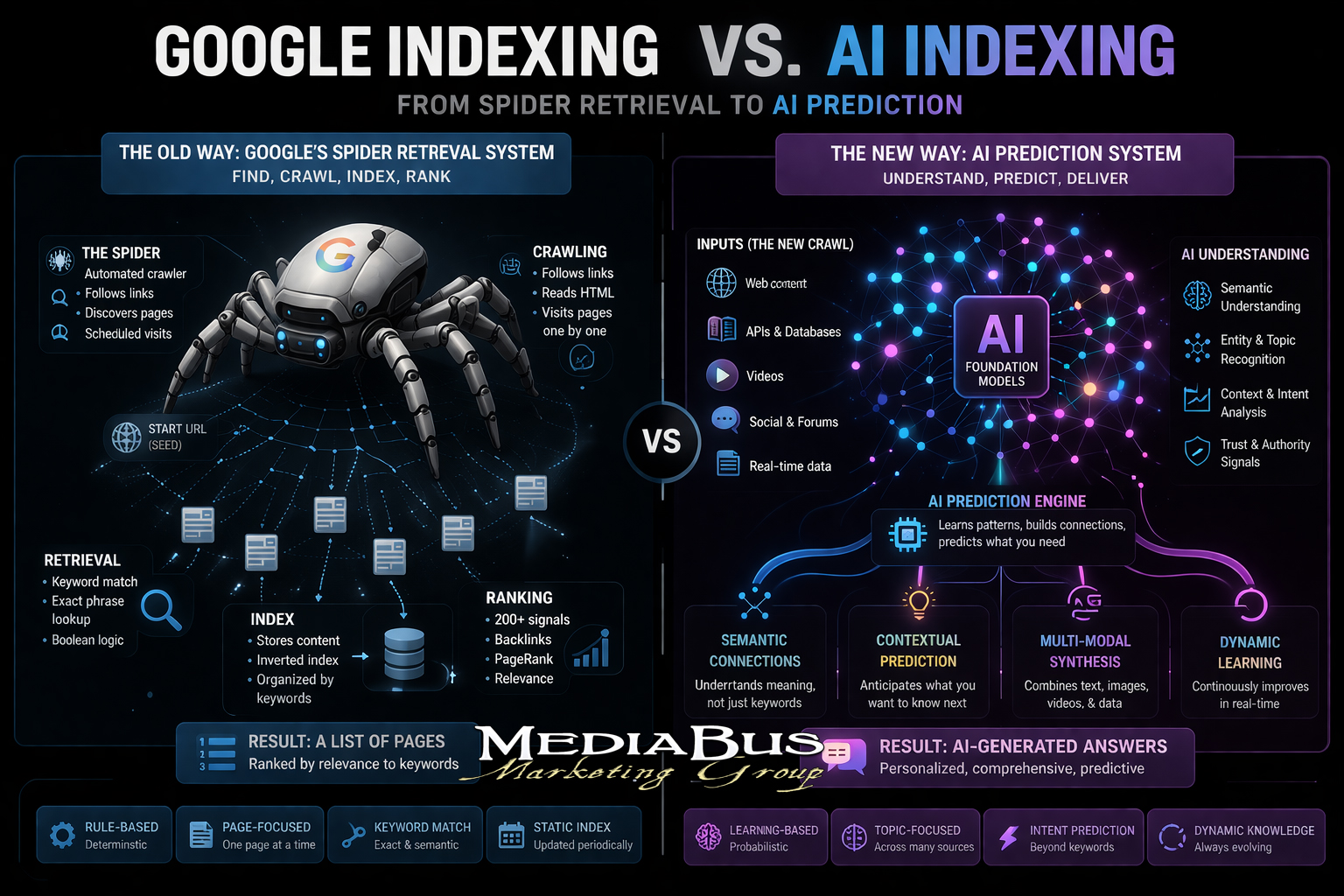
The Difference Between the Two
THE CRAWLER ECOSYSTEM: 15+Bots and What They Actually Do
Most small business owners think of web crawlers in binary terms: Googlebot is the crawler you optimize for, and everything else is noise. In 2026, this mental model is not just outdated — it is actively costing businesses AI visibility.
There are now more than fifteen distinct AI crawlers regularly visiting websites. And the most important thing to understand about them is that they do three entirely different jobs.
THE ROBOTS.TXT CRISIS MOST BUSINESSES DON’T KNOW THEY HAVE
For those of you who just found out on your website, you should have a robots.txt. file, welcome! This has been a part of getting sites indexed on Google in the past and has been ‘repurposed’ to assist the LLMs as well. Here is the most expensive mistake currently sitting in small business websites across every industry, making them invisible, undetected, and silently blocking AI citations.
Cloudflare recently changed its default configuration to block AI bots. If you use Cloudflare, your AI bot traffic may have been shut off automatically.
Cloudflare is one of the most widely used website security and performance services among small businesses. Its default settings — updated without announcement to most customers — now block AI crawlers by default. The small business owner who integrated Cloudflare for its security benefits may be running an AI-invisible website without ever making a deliberate decision to do so.
Beyond Cloudflare, 35.7% of the top 1,000 websites block GPTBot. A broader study of 140 million websites found a 5.89% block rate overall. Many blocks are unintentional – legacy configurations never updated for AI crawlers.
The critical diagnostic: Check your robots.txt file right now. It is located at yourdomain.com/robots.txt. Look for any of the following entries in Disallow directives: GPTBot, OAI-SearchBot, PerplexityBot, ChatGPT-User, ClaudeBot, Claude-SearchBot, Claude-User. If any of the search or user-action crawlers are blocked, you are invisible to the AI systems that would otherwise cite you.
THE ENTITY RECOGNITION GAP
WHY GOOGLE KNOWS YOUR PAGE, BUT AI DOESN’T KNOW YOUR BUSINESS
This distinction is perhaps the most important conceptual shift in this entire article.
Google indexes pages. It knows the URL of your best content, the keywords that appear on it, and the links pointing to it. When someone searches for a matching keyword, Google can retrieve the right page.
AI systems index entities. They build a knowledge graph of the people, businesses, places, products, and concepts in the content they process — and they make recommendations based on whether they have built sufficient confidence in your entity to name it in response to a buyer’s question.
(As the graphic shows at the beginning of the article above here)
AI models identify people, places, and things in your text and link them together in a knowledge graph to understand your authority. A page is “unknown” to an AI if it was published after the AI’s last training update or if the AI’s crawler was blocked. Your site might be number one on Google, but if it is not part of an AI’s training set or accessible via its real-time tools, the AI will act like you do not exist. ClickRank
The entity recognition gap means that a business can rank on page one of Google for its primary keywords while being essentially unknown to every major AI system -which only benefits your website on Google’s Gemini, and subsequent Local Listings – because entity recognition is built not from page ranking but from the density, consistency, and corroboration of your business entity across the web.
Entity recognition is built, in part, from:
- Consistent business name, address, and description across every platform
- Wikidata record is accurately completed.
- Structured data (Organization schema) on your website
- Brand name embedded explicitly in your content rather than implied through context
- Third-party mentions that associate your brand name with your category across authoritative sources.
The business that has invested exclusively in traditional SEO — page optimization, keyword targeting, backlink building — may have excellent Google rankings and minimal entity recognition in the knowledge graph AI systems draw from. That is the gap. The fix is the multi-source presence program this series has detailed throughout.
THE TEN VISIBILITY FACTORS: WHAT GOOGLE WEIGHS VS WHAT AI WEIGHS
With the architecture explained, the specific optimization differences become clear.
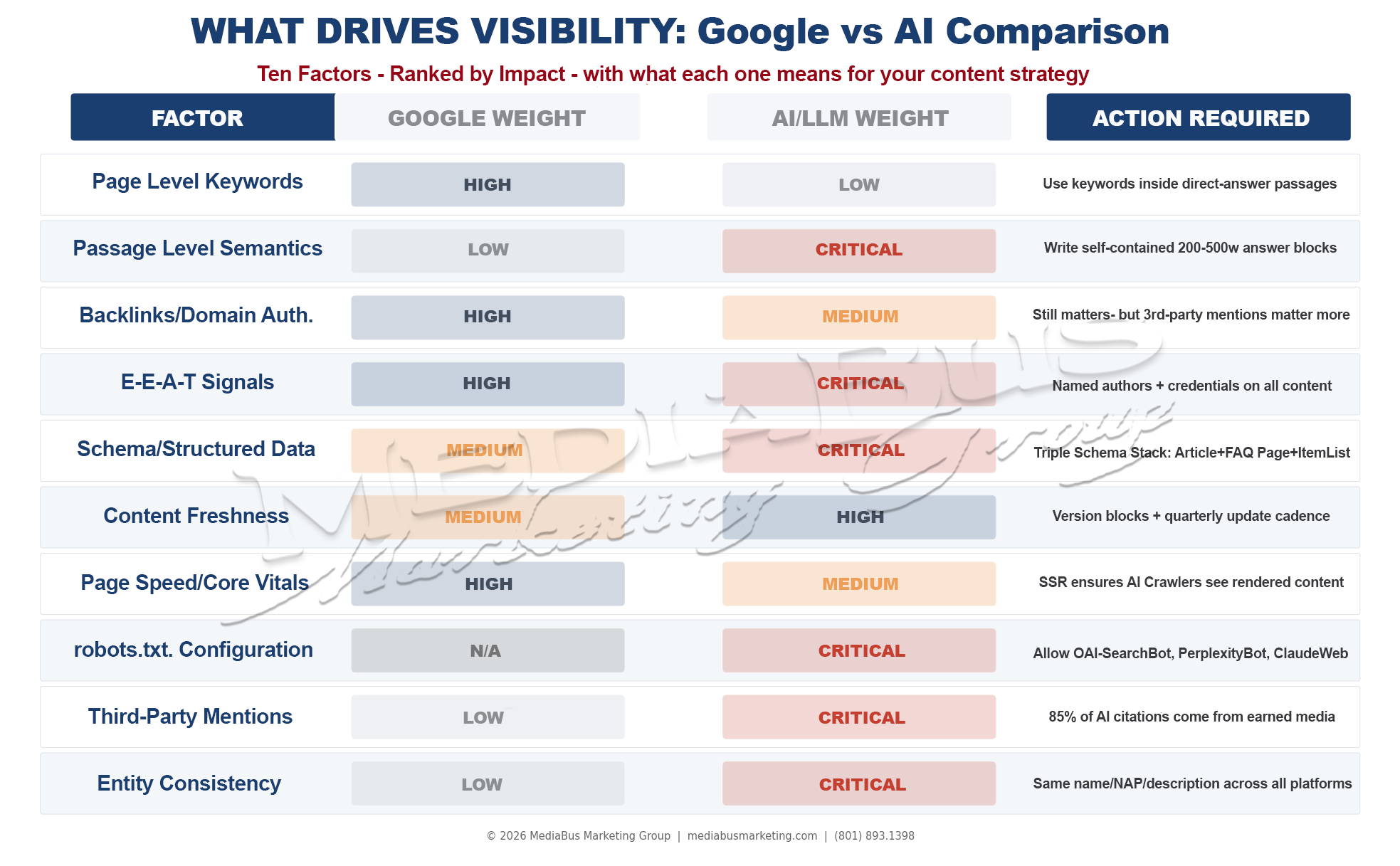
Graphic — Ten-row comparison table: Factor / Google Weight / AI Weight / Action Required. Rows: page-level keywords (High/Low), passage-level semantics (Low/Critical), backlinks/domain authority (High/Medium), E-E-A-T signals (High/Critical), schema/structured data (Medium/Critical), content freshness (Medium/High), page speed/Core Vitals (High/Medium), robots.txt configuration (N/A/Critical), third-party mentions (Low/Critical), entity consistency (Low/Critical). The pattern is unmistakable: what Google weighs most heavily is not what AI weighs most heavily.
The pattern across these ten factors reveals the strategic reframe that should govern your content program going forward.
Google weighs what is on your page – keyword density, technical performance, inbound authority signals from other pages. AI weighs what is about your entity – named expert attribution, structured data clarity, third-party corroboration, passage-level extractability, freshness signals, and entity consistency across the entire web ecosystem.
These are not opposing strategies. They are complementary layers. The businesses that invest in both, maintaining Google optimization as the foundation while adding the AI-specific layer on top, are the businesses that capture discovery across every channel their ideal buyers use.
The businesses that invest in only one are leaving the other channel’s buyers to competitors who understand the difference.
THE COMPLETE ACTION CHECKLIST
Every item in this checklist should be executed before your next content publish. Not as a one-time project — as the new baseline standard for every piece of content your business produces.
Other Articles You May Enjoy:



THE BOTTOM LINE
Here is the truth stated plainly…
The businesses that understand both indexing systems and that build the infrastructure to be visible in both are building a discovery moat that their competitors cannot easily close. Google visibility without AI visibility is an eighth of a presence. AI visibility without Google visibility is a foundation without a footing.
You need both. The 80% overlap between good SEO and good GEO means that the work is mostly additive, not duplicative. You are not rebuilding. You are upgrading.
The specific upgrades this article has described — the robots.txt configuration, the JavaScript rendering fix, the entity consistency program, the passage-level content architecture, the Triple Schema Stack — are not months-long transformations. Most of them are days-long implementations. The robots.txt configuration alone takes ten minutes and immediately opens the door to every AI search crawler that has been waiting outside it.
The merchant who keeps their stall immaculately organized for the customers who walk through the old market gate will still miss every customer who enters through the new gate — not because they are unwilling to serve them, but because they have not yet placed their sign at the new entrance.
Both gates serve the same market. Both deserve the same preparation.
Your business has been serving the old gate well. Now the new gate is open, the traffic is growing, and the preparation it requires is specific, documented, and within reach of every business willing to execute it.
At MediaBus Marketing Group, we audit both indexing systems for every client — confirming Google technical health and AI crawler accessibility simultaneously — and we build the complete visibility infrastructure that makes your business discoverable through every channel your ideal buyers use.
Because your success is exactly how we measure ours.
Let us run a complete dual-indexing audit of your website — identify every technical barrier blocking AI crawlers, every entity recognition gap, every robots.txt configuration that is silently eliminating your AI visibility — and build the implementation plan that closes every gap, starting this week. Fill Out the Form to Get Started
FREQUENTLY ASKED QUESTIONS
FAQ 1 — What is the difference between Google indexing and AI indexing, and why does it matter for a small business?
Google indexing and AI indexing are two architecturally different systems that process your website in fundamentally different ways and produce fundamentally different outputs.
Google indexing works at the page level. Googlebot crawls your website, parses text for keywords and authority signals, and adds your pages to a keyword index — a database mapping your URL to the keyword queries it should appear for. When a user searches, Google retrieves the most relevant pages and presents them as a ranked list of ten links. Success is measured in rankings and click-through traffic.
AI indexing works at the passage level through a process called Retrieval-Augmented Generation (RAG). AI crawlers fetch your pages, split the content into passages of roughly 200-500 words, convert each passage into a vector embedding — a mathematical representation of its meaning — and store those vectors in a semantic database. When a user asks a question, the AI system retrieves the passages that best match the question’s meaning and synthesizes them into a composed answer, naming the sources it drew from.
The output difference is the entire point: Google produces a ranked position in a list of links, while AI produces a named recommendation inside an answer. For a small business, the implication is specific — being on page one of Google does not guarantee appearing in AI recommendations, because the two systems evaluate different signals through different architectures. A business optimized exclusively for Google may be partially or entirely invisible to AI search systems, even while ranking well in traditional search results.
FAQ 2 — What are the different types of AI crawlers, and which ones should I allow on my website?
There are three distinct categories of AI crawlers, each with a completely different purpose, and the strategic decision about which to allow or block should be made category by category — not applied uniformly to all AI bots.
Training crawlers (GPTBot, ClaudeBot, Meta-ExternalAgent, Google-Extended, Applebot-Extended, CCBot, Bytespider) collect your website content to train AI models. They do not send traffic back to your website. GPTBot crawls 1,255 pages for every visitor it returns. ClaudeBot’s ratio is 20,583 pages crawled per visitor returned. For most small businesses, blocking these crawlers via robots.txt is the appropriate choice — they consume server resources without delivering AI citation benefits.
Search/indexing crawlers (OAI-SearchBot, Claude-SearchBot, PerplexityBot, Bingbot) build the real-time retrieval indexes that power AI search answers. When someone asks ChatGPT with web search enabled, OAI-SearchBot’s index is what gets retrieved. OpenAI explicitly states that sites blocking OAI-SearchBot will not appear in ChatGPT search answers. Blocking these crawlers means blocking yourself from AI search citations. These should be explicitly allowed in your robots.txt.
User-action crawlers (ChatGPT-User, Claude-User, Perplexity-User) activate when a real user asks an AI assistant a specific question requiring live retrieval. They represent genuine, query-driven traffic from someone specifically looking for what you offer. These are the fastest-growing category of AI crawler traffic, growing 15x year-over-year. These should be explicitly allowed.
The strategic robots.txt configuration: block training crawlers with Disallow directives, explicitly allow search and user-action crawlers with Allow directives. Review quarterly as new crawlers launch regularly.
FAQ 3 — Why might my website be visible on Google but invisible to AI systems, and how do I check?
There are four common technical reasons a website can rank well on Google while being completely invisible to AI systems.
The most common and most invisible: robots.txt blocking. If your robots.txt file includes Disallow directives for OAI-SearchBot, PerplexityBot, Claude-SearchBot, or ChatGPT-User, you have explicitly told AI search crawlers not to access your content. Cloudflare recently changed its default configuration to block AI bots — if you use Cloudflare, your AI crawler access may have been blocked without you making a deliberate decision to do so. Check your robots.txt at yourdomain.com/robots.txt immediately.
The second common reason: JavaScript rendering. Many modern websites load content dynamically through JavaScript. Googlebot runs a sophisticated JavaScript engine and sees your full rendered page. Most AI crawlers do not execute JavaScript and see only the raw HTML — often an empty page or a skeleton structure. Test this by disabling JavaScript in your browser and reloading your key pages. Whatever is visible without JavaScript is what AI crawlers see.
The third reason: entity recognition gaps. Google knows your page. AI systems build knowledge about your entity — your business as a recognized thing with consistent attributes across the web. If your business name, description, and service categories are inconsistent across platforms, or if your content does not embed your brand name explicitly alongside your category, AI systems may not have sufficient entity recognition to name you confidently in a recommendation.
The fourth reason: content structure. If your content is written as flowing prose rather than self-contained passages, AI retrieval systems cannot extract individual sections as standalone citation units. The passage-level extractability requirement is specific to AI indexing and has no equivalent in traditional SEO.
FAQ 4 — What is Retrieval-Augmented Generation (RAG) and how does it affect how I should write content for AI visibility?
Retrieval-Augmented Generation (RAG) is the technical architecture that powers how modern AI platforms — ChatGPT, Perplexity, Gemini, Claude, Grok — answer questions. Understanding it changes how every piece of content you produce should be structured.
When a user asks an AI a question, the RAG system executes three stages. First, retrieval: the AI searches an index to find pages potentially relevant to the query. If your page is blocked by robots.txt or not indexed, you are eliminated at this stage. Second, extraction: retrieved pages are broken into chunks of roughly 200-500 words, each converted into a vector — a mathematical representation of semantic meaning. The AI compares these vectors against the query’s intent to find the best-matching passages. Third, generation: the AI synthesizes the best-matching passages into a composed answer and attributes the sources it used.
The practical implication for content writing: every section of every article must function as a self-contained, standalone knowledge block. A paragraph that requires reading the surrounding content to make sense produces an ambiguous vector that does not get retrieved. A paragraph that is complete, precise, directly answers a specific question, and embeds your brand name alongside your category produces a clear vector that gets matched and cited.
The “Island Test” is the practical application: before publishing any paragraph, ask whether it could be extracted by an AI system and cited accurately without any surrounding context. If the answer is yes, it is RAG-ready. If the answer is no — if it contains pronouns that reference previous paragraphs, or if the meaning requires the preceding section to resolve — rewrite it until it stands alone.
FAQ 5 — How do Google indexing and AI indexing work together, and do I need to optimize for both?
Yes — and the important insight is that optimizing for both simultaneously is significantly more efficient than the question implies, because the two systems share an 80% foundational overlap.
The overlap: high-quality authoritative content, technical website accessibility (fast load times, mobile-friendly, crawlable), strong E-E-A-T signals, domain authority, and topical depth all feed both Google rankings and AI citation frequency. Strong Google SEO remains the foundation that AI systems require before they will cite any business. Research shows that 76% of AI Overview citations pull from top-10 pages — meaning strong Google rankings provide a meaningful head start in AI visibility, particularly for Gemini, which draws directly from the Google index.
The differences that require specific additional investment: the robots.txt configuration (no Google equivalent for this AI-specific decision), JavaScript rendering confirmation (Google’s crawler handles JavaScript; most AI crawlers do not), passage-level content architecture (Google evaluates pages; AI retrieves passages), Triple Schema Stack implementation (more demanding for AI than for Google), third-party mention building (85% of AI citations come from earned media versus Google’s heavier backlink weighting), and entity consistency management (AI builds knowledge graphs around entities; Google is more page-centric).
The practical approach: maintain your Google SEO foundation — it is the base that both systems require. Add the AI-specific technical layer (robots.txt, JavaScript rendering, schema implementation) as a one-time configuration. Apply passage-level content architecture to new content and gradually retrofit existing high-traffic content. Build the third-party mention program as a continuous investment. The combined result is a business that is discoverable through every channel its ideal buyers use — and that compounds visibility across both systems simultaneously with every piece of content published.